Linus:利用二级指针删除单向链表
感谢网友full_of_bull投递此文(注:此文最初发表在这个这里,我对原文后半段修改了许多,并加入了插图)
Linus大婶在slashdot上回答一些编程爱好者的提问,其中一个人问他什么样的代码是他所喜好的,大婶表述了自己一些观点之后,举了一个指针的例子,解释了什么才是core low-level coding。
下面是Linus的教学原文及翻译——
“At the opposite end of the spectrum, I actually wish more people understood the really core low-level kind of coding. Not big, complex stuff like the lockless name lookup, but simply good use of pointers-to-pointers etc. For example, I’ve seen too many people who delete a singly-linked list entry by keeping track of the “prev” entry, and then to delete the entry, doing something like。(在这段话的最后,我实际上希望更多的人了解什么是真正的核心底层代码。这并不像无锁文件名查询(注:可能是git源码里的设计)那样庞大、复杂,只是仅仅像诸如使用二级指针那样简单的技术。例如,我见过很多人在删除一个单项链表的时候,维护了一个”prev”表项指针,然后删除当前表项,就像这样)”
if (prev)
prev->next = entry->next;
else
list_head = entry->next;
and whenever I see code like that, I just go “This person doesn’t understand pointers”. And it’s sadly quite common.(当我看到这样的代码时,我就会想“这个人不了解指针”。令人难过的是这太常见了。)
People who understand pointers just use a “pointer to the entry pointer”, and initialize that with the address of the list_head. And then as they traverse the list, they can remove the entry without using any conditionals, by just doing a “*pp = entry->next”. (了解指针的人会使用链表头的地址来初始化一个“指向节点指针的指针”。当遍历链表的时候,可以不用任何条件判断(注:指prev是否为链表头)就能移除某个节点,只要写)
*pp = entry->next
So there’s lots of pride in doing the small details right. It may not be big and important code, but I do like seeing code where people really thought about the details, and clearly also were thinking about the compiler being able to generate efficient code (rather than hoping that the compiler is so smart that it can make efficient code *despite* the state of the original source code). (纠正细节是令人自豪的事。也许这段代码并非庞大和重要,但我喜欢看那些注重代码细节的人写的代码,也就是清楚地了解如何才能编译出有效代码(而不是寄望于聪明的编译器来产生有效代码,即使是那些原始的汇编代码))。
Linus举了一个单向链表的例子,但给出的代码太短了,一般的人很难搞明白这两个代码后面的含义。正好,有个编程爱好者阅读了这段话,并给出了一个比较完整的代码。他的话我就不翻译了,下面给出代码说明。
如果我们需要写一个remove_if(link*, rm_cond_func*)的函数,也就是传入一个单向链表,和一个自定义的是否删除的函数,然后返回处理后的链接。
这个代码不难,基本上所有的教科书都会提供下面的代码示例,而这种写法也是大公司的面试题标准模板:
typedef struct node
{
struct node * next;
....
} node;
typedef bool (* remove_fn)(node const * v);
// Remove all nodes from the supplied list for which the
// supplied remove function returns true.
// Returns the new head of the list.
node * remove_if(node * head, remove_fn rm)
{
for (node * prev = NULL, * curr = head; curr != NULL; )
{
node * const next = curr->next;
if (rm(curr))
{
if (prev)
prev->next = next;
else
head = next;
free(curr);
}
else
prev = curr;
curr = next;
}
return head;
}
这里remove_fn由调用查提供的一个是否删除当前实体结点的函数指针,其会判断删除条件是否成立。这段代码维护了两个节点指针prev和curr,标准的教科书写法——删除当前结点时,需要一个previous的指针,并且还要这里还需要做一个边界条件的判断——curr是否为链表头。于是,要删除一个节点(不是表头),只要将前一个节点的next指向当前节点的next指向的对象,即下一个节点(即:prev->next = curr->next),然后释放当前节点。
但在Linus看来,这是不懂指针的人的做法。那么,什么是core low-level coding呢?那就是有效地利用二级指针,将其作为管理和操作链表的首要选项。代码如下:
void remove_if(node ** head, remove_fn rm)
{
for (node** curr = head; *curr; )
{
node * entry = *curr;
if (rm(entry))
{
*curr = entry->next;
free(entry);
}
else
curr = &entry->next;
}
}
同上一段代码有何改进呢?我们看到:不需要prev指针了,也不需要再去判断是否为链表头了,但是,curr变成了一个指向指针的指针。这正是这段程序的精妙之处。(注意,我所highlight的那三行代码)
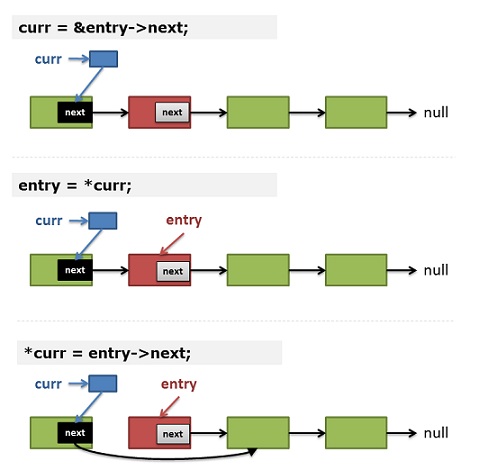
让我们来人肉跑一下这个代码,对于——
- 删除节点是表头的情况,输入参数中传入head的二级指针,在for循环里将其初始化curr,然后entry就是*head(*curr),我们马上删除它,那么第8行就等效于*head = (*head)->next,就是删除表头的实现。
- 删除节点不是表头的情况,对于上面的代码,我们可以看到——
1)(第12行)如果不删除当前结点 —— curr保存的是当前结点next指针的地址。
2)(第5行) entry 保存了 *curr —— 这意味着在下一次循环:entry就是prev->next指针所指向的内存。
3)(第8行)删除结点:*curr = entry->next; —— 于是:prev->next 指向了 entry -> next;
是不是很巧妙?我们可以只用一个二级指针来操作链表,对所有节点都一样。
如果你对上面的代码和描述理解上有困难的话,你可以看看下图的示意:
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)







 (54 人打了分,平均分: 4.28 )
(54 人打了分,平均分: 4.28 )
《Linus:利用二级指针删除单向链表》的相关评论
@超然
*curr = &entry->next固然没错,但是next必须放在最前面,为什么??因为表头啊!
listelem ** head;
head = &firstelem.next;
然后我可以用*head来访问表头里的其他元素
head->item1
head->item2
…….
明白了么???
如果你把next放在结构体的其他地方,head就只能用来访问表头的next指针了,这样表头里的其他元素就不能用了!
viho_he说的更大错特错*curr = (node **)entry,entry是一个一级指针,怎么转成二级指针?如果允许那是非常危险的!
没错,如果next放在第一个字段上,那么
curr = &entry->next;
entry = *curr;
这两句意义就是如果entry指向当前节点,那么curr指向前一节点,*curr指向当前节点,**curr指向下一节点(***curr指向第四个节点),好处就是一个变量引用多个节点。
换言之,如果一个单向链表,next是第一个字段,我们可以用一个二级指针dummy引用一条链表上的所有节点。
struct node **dummy = &head->next;
一次解引用*dummy指向头结点head
二次解引用**dummy指向head下一个节点
三次解引用*(*(*dummy))指向第三个节点
以此类推……
如果我们需要找到从head开始的第N个节点,那么对dummy进行N次解引用即可,当然现实工程中一般不会用到这么tricky的语法糖,但使用一个变量同时引用相邻三个节点是很有用的;-)。
给还不明白的同学论证一下,见如下代码
typedef struct list_s{
struct list_s * next;
int a;
int b;
} list_t;
main()
{
list_t lA, lB, lC, lD;
list_t ** phead = &lA.next;
lA.next = &lB;
lA.a = 11;
lA.b = 12;
lB.next = &lC;
lB.a = 21;
lB.b = 22;
lC.next = &lD;
lC.a = 31;
lC.b = 32;
lD.next = NULL;
lD.a = 41;
lD.b = 42;
printf(“%d\n”, ((list_t *)phead)->a);
printf(“%d\n”, (**(list_t**)phead).a);
printf(“%d\n”, (***(list_t***)phead).a);
printf(“%d\n”, (****(list_t****)phead).a);
printf(“%d\n”, ((list_t *)phead)->b);
printf(“%d\n”, (**(list_t**)phead).b);
printf(“%d\n”, (***(list_t***)phead).b);
printf(“%d\n”, (****(list_t****)phead).b);
}
gcc的结果是
11
21
31
41
12
22
32
42
嗯,很不错,受益匪浅,支持下
linux内核使用的双向链表,就是这个链表的基础上的扩展的,大家有空可以去看下,非常不错。
删除节点操作实质上就是修改某些节点的指针域,比如删除的是头节点就要修改头指针指向新的节点,删除的不是头节点就要修改前面一个节点的指针域。而修改指针域我们直接用一个指向这个指针的指针去引用就可以了,不用再去通过object去引用里面的指针域。
@zz
正解啊。
@fox的爱智慧
用GDB在x86下的FC11上打印了一下:
(gdb) p &lA
$24 = (list_t *) 0xbffff3a0
(gdb) p &lB
$25 = (list_t *) 0xbffff394
(gdb) p &lC
$26 = (list_t *) 0xbffff388
(gdb) p &lD
$27 = (list_t *) 0xbffff37c
(gdb) p phead
$28 = (list_t **) 0xbffff3a0
(gdb) p *(list_t *)phead
$29 = {next = 0xbffff394, a = 11, b = 12}
(gdb) p **(list_t **)phead
$30 = {next = 0xbffff388, a = 21, b = 22}
(gdb) p ***(list_t ***)phead
$31 = {next = 0xbffff37c, a = 31, b = 32}
(gdb) p ****(list_t ****)phead
$32 = {next = 0x0, a = 41, b = 42}
(gdb)
对指针理解的更深入了,谢谢
学习了,感谢Leo.
学习了,
不过我觉得这里的重点不是怎么用指针,
而是发现head和next在逻辑上的一致性。
@fox的爱智慧
如果next不是在第一字段,那么,*phead就不是指向head的吧?而是指向head->next
@fox的爱智慧
我这句话其实多余了,前面的评论已经讲得很清楚了,汗·····前面的评论太长,没来得及看
@FBW
我的第一句表达有问题“*phead就不是指向head的吧?”,这句话严格的说,*phead指的是,头指针head所对应的结构体,不是指针head本身,免得又让人误会
看了好久才看懂,受益了
可以这么理解,二级指针void **pnode 相当于汇编的间接寻址,内存上可以理解为直接操作两个存储单元,一个储存链表的前一个节点地址(pnode的值),另一个储存当前节点地址(*pnode的值),所以*pnode = entry->next 就将当前的节点换成下个节点,但仍旧保持pnode的值,即上个节点值不变;pnode=&entry->next,则直接更改上个指针指向的地址,跳到下个节点处理。
@guyot
同意这个说法。引入的二级指针,使得head变成了只包含一个指针的dummy链表节点,而二级指针作为新的head指向他。实际遍历的时候就没有head之分了。
因为我这里没准备 C compiler,而且也不会用 GDB 啥的,估计用了也是头晕,因为 X86 指令集的地址应该蛮长的,我的算术水平仅限个位数加法——总之,对于这种高难度而不复杂的问题,我在查阅了一备 K&R C 之后,发明了一套 debug on paper 的方法……
linus 这个命题的关键部分在于,prev 到哪里去了,而实际上 prev->next 指向 entry(但是这点非常隐蔽,linus 你还能再坏一点么),也就是说,prev->next entry *curr 这三个指针是同一地址,curr 在作用在于,当 rm(entry) 之后,*curr 仍然维护着 prev->next 的地址
仔细研究了 *curr = entry->next; 和 curr = &entry->next; 两句的区别,猛一看,似乎真没什么区别……如果不考虑隐身的 prev->next ,实际上真的没有区别(刚翻 K&R C 的时候没有找到相关内容,估且认为没有区别吧-_-!!!)
然后再把所有的二级指针换成一级指针,还是没有区别……可能是我不懂 C,没有看出里面的深意……所以我编了几个简单的地址&一个长度为 3 在链表,在纸上进行调试……上面的结论是用第 2 个 node 试验时得出的。如果是第 1 个 node ,因为几乎不懂 C ,所以不知道 prev->next 在各种 NULL 的情况下,会有什么结果。尽管这实际上是最重要的(涉及到 head),但是我觉得楼上各位的讨论方向错了啊
当然更大的可能是我弄错了,毕竟我也就是个半吊子的 lisp 爱好者
看错了,原来并不是先删除 entry,不过道理还是差不多的,因为剧情需要 prev->next 不能出现,所以 *curr 和 entry 都保存着 prev->next 的地址(一个地址弄两份,就是一个断后,一个撤退的意思),但是这个地址如果没有用 curr 引用着的话 ,rm(entry) 后应该一起删除了,因为是同一个地址……反正就是删除对象后引用会不会同死之类的问题了,都是细节,具体我也不清楚……无伤大雅就是了
我觉得这个不是理解指针和链表的问题。其实从逻辑上看,第一段代码对指针和链表的理解就是足够的。所谓“core low-level coding”,这个是指有了第一段代码之后,对编译器实际生成的代码的执行过程有一个想象,能够写出更底层更优化的代码
@fanhe 分析的很好!确实,这种方案就是见了一个虚拟的dummy node。不过,我觉得这种方案不存在你说的返回新的头的问题吧,新的head会体现在你传入的二级指针上吧,不需要额外的操作了
确实,我之前还在想要返回新的头节点怎么办,你这一说我明白了,调用者的*head就是新的头节点的地址。linux这个方法确实妙,就是对指针理解不深入的人很难搞懂。
@fox的爱智慧
这个也太trick了,必须保证next指针在结构体的最前面……
不需要next在结构体最前,那个人理解有误。
俺是小菜,对最后一个程序的第8行和第12行不是很理解。
*curr = entry->next;
curr = &entry->next;
这两句看起来作用差不多,但是实际还是有差别的吧。假如修改了*curr,那么*head的值也会被修改吧。
例如外层的程序调用时remove_if( &pHead, pRemove),那么pHead也会被修改吧,会指向最后一个符合删除条件的下一个节点。但是pHead不应该被修改啊……
因此感觉这个程序不太对。
因此俺觉得第8行和第12行应该都用curr = &entry->next;
这样可以保证*curr指向下一个节点,而*head保持不变。
不知道这样想对不对啊……
@HCocoa
但是这样一来就没法删除表头节点了,残念啊……
不好意思,一开始没有理解,刚才洗澡的时候想通了……文章里的程序是正确的。
麻烦博主删除俺的评论,避免误人子弟,荼毒大众……
二级指针确实可以在逻辑上达到删除目的,但是是有风险的。
毕竟他改变了链表中删除节点后面结点的内存地址。
A->B->C 删除B
二级指针的方法相当于把C的内存拷贝到B了。就是*curr = entry->next;这句。
发现想错了,求删除@gykgod
我觉得删除当前节点的本质就是,在原先引用了当前节点的地方(node** curr),改值为当前节点的下一个节点(*curr = entry->next;)。这样理解就很简单了。
很明显,第二种方案无法删除链表第一个结点,除非存在一个辅助的头结点,即C++ STL里边类似slist的实现方式
@Hetiu
或者需要一个指向第一个结点的指针:
node *firstnode = &nodelist; // nodelist 是链表的第一个结点
node **head = &firstnode;
@guyot
厉害,一句话总结全文!
牛!
感谢博主分享,不过好像插图有一点问题。
初始化curr = head后,curr指向“小紫色块”,“小紫色块”指向第一个“绿色块”。
在执行curr = &entry->next后,应该变成:
curr指向第一个“绿色块”中的“next块”,“该next块”指向第二个“绿色块”。(图中为curr指向“小紫色块”,“小紫色块”指向第一个“绿色块”中的“next块”,“该next块”指向第二个“绿色块”)
从直观上来看,由于curr是node**类型,故curr应该沿着“箭头”走2步即到达node节点(小绿色块)。而图中走了3步。
如果按照guyot的说法来理解,“小紫色块”就是“虚拟的头”。在执行curr = &entry->next后,链表向右移动了一位,也就不需要“虚拟的头”了。
linus 确实好优秀…
感觉我这个也还行,求鉴定:
node * remove_if(node * head, remove_fn rm) {
if(head == NULL)
return head;
node* ret = head; //头留到最后处理
while(head->next != NULL)
{
if(fn(head->next))
{
node* tmp = head->next;
head->next = tmp->next;
free(tmp);
}
else
head = head->next;
}
if(fn(ret))
{
node* tmp = ret->next;
free(ret);
return tmp;
}
else
return ret;
}
虚拟改成匿名会更恰当
每次保存 &(node->next), 即直接操作next,而并非&(node) —— low-level coding
因为要操作的是指针域,而非node成员,因此,需要二级指针指向需要操作的指针。