Cuckoo Filter:设计与实现
(感谢网友 @我的上铺叫路遥 投稿)

对于海量数据处理业务,我们通常需要一个索引数据结构,用来帮助查询,快速判断数据记录是否存在,这种数据结构通常又叫过滤器(filter)。考虑这样一个场景,上网的时候需要在浏览器上输入URL,这时浏览器需要去判断这是否一个恶意的网站,它将对本地缓存的成千上万的URL索引进行过滤,如果不存在,就放行,如果(可能)存在,则向远程服务端发起验证请求,并回馈客户端给出警告。
索引的存储又分为有序和无序,前者使用关联式容器,比如B树,后者使用哈希算法。这两类算法各有优劣:比如,关联式容器时间复杂度稳定O(logN),且支持范围查询;又比如哈希算法的查询、增删都比较快O(1),但这是在理想状态下的情形,遇到碰撞严重的情况,哈希算法的时间复杂度会退化到O(n)。因此,选择一个好的哈希算法是很重要的。
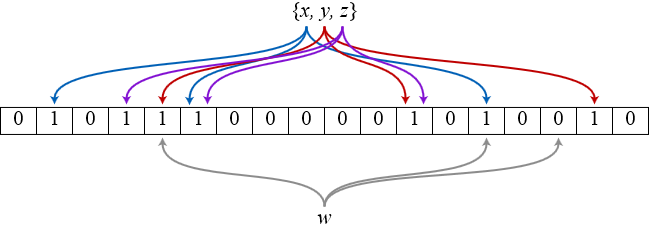
时下一个非常流行的哈希索引结构就是bloom filter,它类似于bitmap这样的hashset,所以空间利用率很高。其独特的地方在于它使用多个哈希函数来避免哈希碰撞,如图所示(来源wikipedia),bit数组初始化为全0,插入x时,x被3个哈希函数分别映射到3个不同的bit位上并置1,查询x时,只有被这3个函数映射到的bit位全部是1才能说明x可能存在,但凡至少出现一个0表示x肯定不存在。

 (51 人打了分,平均分: 4.20 )
(51 人打了分,平均分: 4.20 ) 关于性能优化这是一个比较大的话题,在《
关于性能优化这是一个比较大的话题,在《 (47 人打了分,平均分: 4.28 )
(47 人打了分,平均分: 4.28 )

